数据标注任务简介
有灵平台支持如下的数据标注任务类型:
| 场景 | 说明 |
|---|---|
| 图片分类 | 对单张图片进行分类,如猫狗分类,支持单选、多选 |
| 图片选择 | 从多张图片中选择一个或多个 |
| 图片打分 | 对单张图片进行打分 |
| 文本分类 | 从一段文本中进行分类,支持单选、多选 |
| 文本选择 | 从多个文本中选择一个 |
| 文本打分 | 对一段文本进行打分 |
| 音频分类 | 对单个音频进行分类,如是否包含关键词,支持单选、多选 |
| 视频分类 | 对单个视频进行分类 |
图片分类 Demo
通过有灵平台发布一个对单张图片进行猫狗分类的众包任务,并获取标注结果。
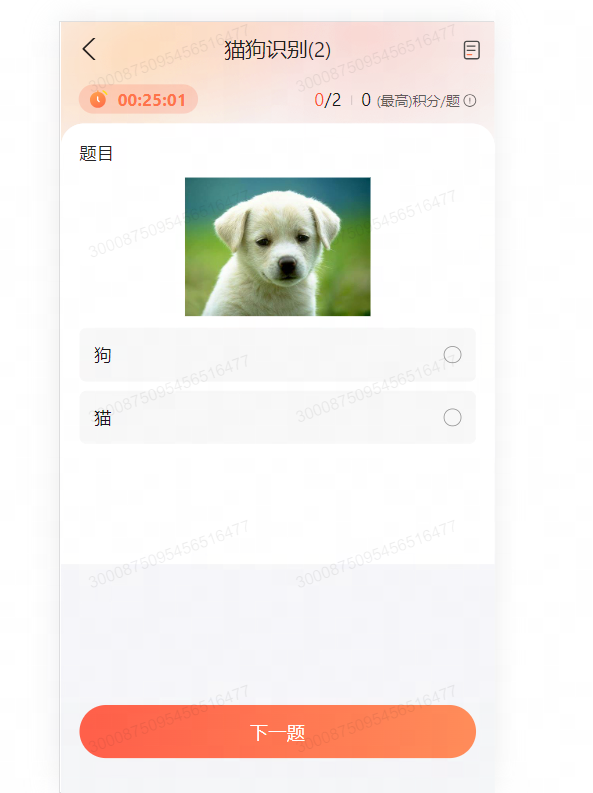
IDL
以下代码示例了通过 IDL 定义猫狗分类任务、智能体及智能体能力。可自定义修改名称。
说明:
- Aop_Zhongbao 为任务名称。
- Aop_Agent 为智能体名称。
- annotate 为智能体标注能力,输入一张图片,输出一个分类结果。
- 能力的输入为 Observation【Image】 类型。
- 能力的输出为 MemState【CatCategory】类型,可以通过输出获取置信度。
#!/usr/bin/env python3
from fuxi.aop.edsl import *
from typing import List, Literal
''' 定义众包页面展示的选项'''
class CatCategory (IntEnum):
狗 = 0
猫 = 1
class Aop_Zhongbao(Task):
''' 定义众包任务 '''
class Aop_Agent(Agent):
''' 定义众包智能体 '''
a: Observation[Image]
b: MemState[CatCategory]
@cognition(
category = "Human",
input = ['a'],
output = ['b'],
persistent = True,
)
def annotate():
''' 标注能力'''
if __name__ == "__main__":
main(Aop_Zhongbao)
客户端代码
以下代码示例了在客户端调用智能体能力,对一张图片进行分类标注。可自定义修改变量名称。
说明:
- 获取一个事件循环对象,并运行 main 函数,直到它完成(所有的异步操作都执行完毕)。
- main 函数通过调用 AOP.init 方法初始化了一个名为 aop 的对象。
- 使用 aop.create_agent 方法创建了一个名为 agent 的智能体。
- 使用 AOP SDK 内置方法 builtins.Image.from_path_async 方法异步加载了一张图片,并将其存储在 image1 变量中。支持格式:'jpg', 'bmp', 'png', 'webp', 'gif'。
- 调用智能体能力 agent.annotate,输入为 Observation[Image] 类型的参数 a。
- output 为智能体能力 agent.annotate 的返回值,MemState[CatCategory] 类型。
- 通过打印 output.confidence 展示本次标注结果的置信度。
import os
import sdk
import asyncio
from fuxi.aop.core import AOP
import fuxi.aop.ddl.builtins as builtins
from fuxi.aop.edsl import State, Action, Observation, MemState
from typing import List, Set, Dict, Tuple, Optional, Callable, TypeVar, Generic, Any, Union, Literal
from fuxi.aop.ddl.builtins import Image
from sdk.aop_dataclasses import CatCategory, Aop_AgentObservation, Aop_AgentState, Aop_AgentAction, Aop_AgentMemState
async def main():
aop = await AOP.init(task_type = sdk.Aop_Zhongbao, config = sdk.get_server_config("10505"))
agent = await aop.create_agent(sdk.Aop_Agent)
image1 = await builtins.Image.from_path_async('./test1.jpg','jpg')
a = Observation[Image](image1)
output = await agent.annotate(a) # call capability function
print(output.confidence)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())语音分类 Demo
通过有灵平台发布一个对音频内容进行分类的众包任务,并获取标注结果。
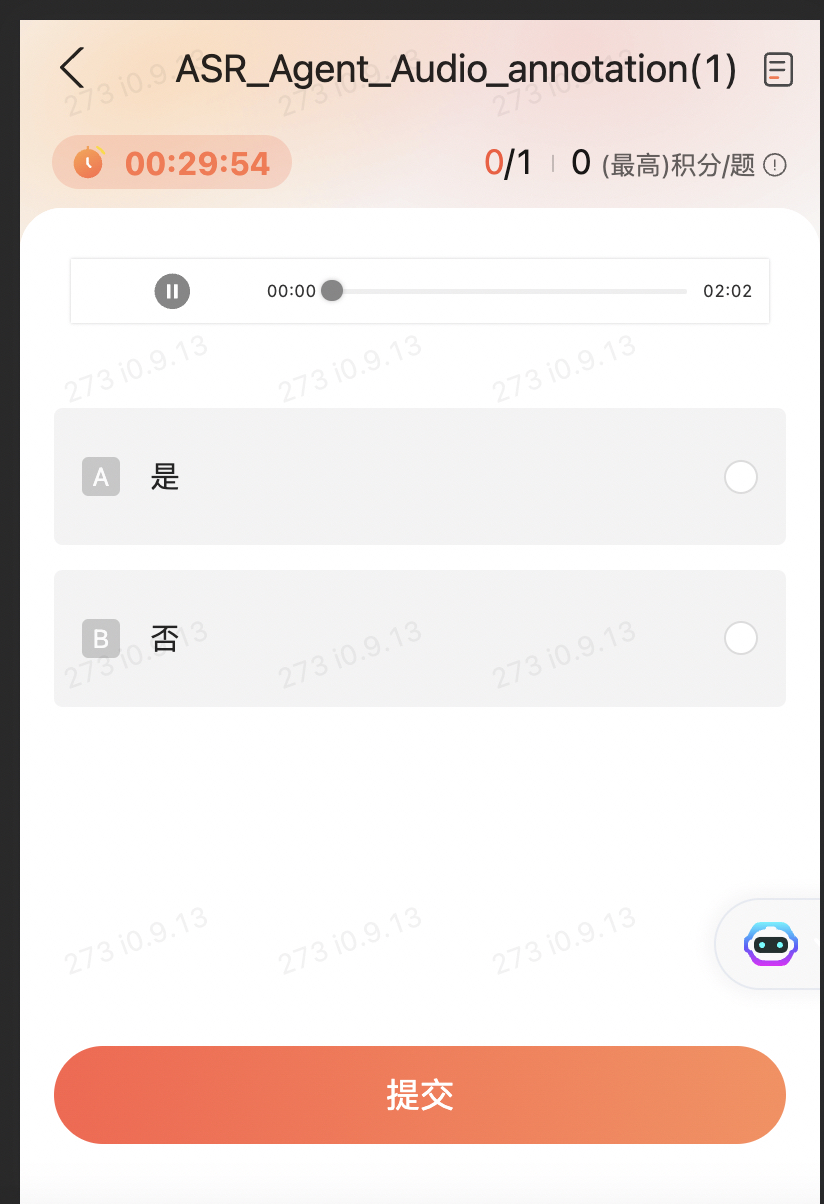
IDL
以下代码示例了通过 IDL 定义语音分类任务、智能体及智能体能力。可自定义修改名称。
说明:
- ASR_Annotation_Task 为任务名称。
- ASR_Agent 为智能体名称。
- audio_annotation 为智能体标注能力,输入一个音频,输出一个分类结果。
- 能力的输入为 Observation【Audio】 类型,类型说明。
- 能力的输出为 MemState【CheckEnum】 类型,可以通过输出获取置信度,类型说明。
from fuxi.aop.edsl import *
from typing import List, Literal,Tuple
from fuxi.aop.ddl.builtins import Audio
''' 定义众包页面展示的选项'''
class CheckEnum (IntEnum):
是 = 0
否 = 1
class ASR_Annotation_Task(Task):
''' 定义众包任务 '''
class ASR_Agent(Agent):
''' 定义众包智能体 '''
a: Observation[Audio]
b: MemState[CheckEnum]
@cognition(
category = "Human",
input = ['a'],
output = ['b'],
persistent = True,
)
def audio_annotation():
''' 判断音频内容 '''
...
if __name__ == "__main__":
main(ASR_Annotation_Task)
客户端代码
以下代码示例了在客户端调用智能体能力,对一张图片进行分类标注。可自定义修改变量名称。
说明:
- 获取一个事件循环对象,并运行 main 函数,直到它完成(所有的异步操作都执行完毕)。
- main 函数通过调用 AOP.init 方法初始化了一个名为 aop 的对象。
- 使用 aop.create_agent 方法创建了一个名为 agent 的智能体。
- 使用 AOP SDK 内置方法 builtins.Audio.from_path_async 方法异步加载了一个音频,并将其存储在 audio1 变量中。支持格式:'mp3', 'wav', 'ogg', ‘opgg’。
- 调用智能体能力 agent.audio_annotation ,输入为 Observation[Audio] 类型的参数 a。
- output 为智能体能力 agent.audio_annotation 的返回值,MemState[CheckEnum] 类型。 通过打印 output.confidence 展示本次标注结果的置信度。
import os
import sdk
import asyncio
from fuxi.aop.core import AOP
import fuxi.aop.ddl.builtins as builtins
from fuxi.aop.ddl.builtins import Audio
from fuxi.aop.edsl import State, Action, Observation, MemState
from typing import List, Set, Dict, Tuple, Optional, Callable, TypeVar, Generic, Any, Union, Literal
from sdk.aop_dataclasses import CheckEnum, ASR_AgentObservation, ASR_AgentState, ASR_AgentAction, ASR_AgentMemState
async def main():
aop = await AOP.init(task_type = sdk.ASR_Annotation_Task, config = sdk.get_server_config("10505"))
agent = await aop.create_agent(sdk.ASR_Agent)
audio1 = await builtins.Audio.from_path_async('./test.wav','wav')
a = Observation[Audio](audio1)
output = await agent.audio_annotation(a) # call capability function
print(output.confidence)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
视频分类 Demo
通过有灵平台发布一个对视频内容进行分类的众包任务,并获取标注结果。
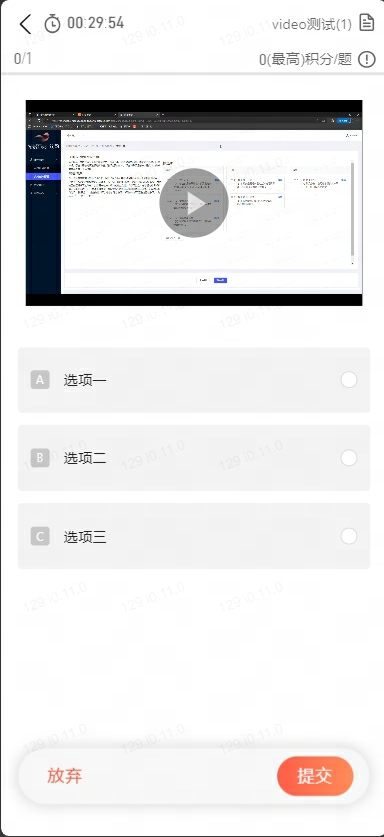
IDL
以下代码示例了通过 IDL 定义语音分类任务、智能体及智能体能力。可自定义修改名称。
说明:
- Annotation_Task 为任务名称。
- A_Agent 为智能体名称。
- video_test 为智能体标注能力,输入一个音频,输出一个分类结果。
- 能力的输入为 Observation【Video】 类型。
- 能力的输出为 MemState【TextEnum】 类型,可以通过输出获取置信度。
from fuxi.aop.edsl import *
from typing import List, Literal,Tuple
from fuxi.aop.ddl.builtins import Video
class TextEnum (IntEnum):
选项一 = 0
选项二 = 1
选项三 = 2
class Annotation_Task(Task):
class A_Agent(Agent):
''' nlp '''
video:Observation[Video]
type:MemState[TextEnum]
@cognition(
category = "Human",
persistent = True,
input = ["video"],
output= ["type"],
)
def video_test(self):
''' 测试视频 '''
...
if __name__ == "__main__":
main(Annotation_Task)
客户端代码
以下代码示例了在客户端调用智能体能力,对一段视频进行分类标注。可自定义修改变量名称。
说明:
- 获取一个事件循环对象,并运行 main 函数,直到它完成(所有的异步操作都执行完毕)。
- main 函数通过调用 AOP.init 方法初始化了一个名为 aop 的对象。
- 使用 aop.create_agent 方法创建了一个名为agent 的智能体。
- 使用 AOP SDK 内置方法builtins.Video.from_path_async 方法异步加载了一个视频,并将其存储在 video1 变量中。支持格式:'mp4', 'mov', 'mkv'。
- 调用智能体能力 agent.video_test ,输入为 Observation[Video] 类型的参数 a。
- output 为智能体能力 agent.video_test的返回值,MemState[CheckEnum] 类型。
- 通过打印 output.confidence 展示本次标注结果的置信度。
import os
import sdk
import asyncio
from fuxi.aop.core import AOP
import fuxi.aop.ddl.builtins as builtins
from fuxi.aop.ddl.builtins import Video
from fuxi.aop.edsl import State, Action, Observation, MemState
from typing import List, Set, Dict, Tuple, Optional, Callable, TypeVar, Generic, Any, Union, Literal
from sdk.aop_dataclasses import CheckEnum, ASR_AgentObservation, ASR_AgentState, ASR_AgentAction, ASR_AgentMemState
async def main():
aop = await AOP.init(task_type = sdk.A_Annotation_Task, config = sdk.get_server_config("10505"))
agent = await aop.create_agent(sdk.A_Agent)
video1 = await builtins.Video.from_path_async('./test.mp4','mp4')
a = Observation[Video](video1)
output = await agent.video_test(a) # call capability function
print(output.confidence)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())其他类型任务
选择任务 IDL 示例
class AOP_Task(Task):
class AOP_Agent(Agent):
input_list:State[Vector[Image,size[2]]] # 备选项列表,需要指定一个有限列表,列表内容可以为str\image\audio\video
output_choosen:State[Literal[0,1]] # 需要输出备选项中的第几个,内容根据备选项个数确定
@cognition(
category = "Human",
persistent = True,
input = ["input_list"],
output = ["output_choosen"],
)
def aopDemo(self):
''' 选择任务 '''
...
打分任务 IDL 示例
class AOP_Task(Task):
class AOP_Agent(Agent):
aes_score: State[Annotated[int, ValueRange(0,5,1), Desc("美观度")]]
com_score: State[Annotated[float, ValueRange(0,10,step=0.5), Desc("完整度")]]
input_image: State[Image] #这里以图片为例,可以是Image,Video,Audio,str
# Range(最小值,最大值,步长),ValueRange(0,10,step=2),用户可以打0、2、4、6、8、10
# int默认步长 1,float默认步长 0.1,float最小精度为0.1
# Desc("美观度"),美观度用于C端页面显示,比如打分组件的标签
# ValueRange(0,5),(0,5)两端都是闭区间
@cognition(
category = "Human",
persistent = True,
input = ["input_image"],
output = ["aes_score"],
)
def one_image_one_rating(self):
''' 一个图片一个分数的打分任务 '''
...
@cognition(
category = "Human",
persistent = True,
input = ["input_image"],
output = ["aes_score","com_score"],
)
def one_image_multi_dimension_rating(self):
''' 一个图片多个维度分数的打分任务 '''
...多道题客户端示例
客户端-发题:同步调用,获取结果
- 以下示例了发送 3 道题,同步调用智能体能力 agent.audio_annotation
- 如果需要发送大数据量,请在本地使用多线程,需要测试一下速度,设置线程数
举例:以某图片单选任务,一个线程发 10000 道题耗时 1.5 小时左右;最终使用 10 个线程并发发送 50000 条
import os
import sdk
import asyncio
from fuxi.aop.core import AOP
import fuxi.aop.ddl.builtins as builtins
from fuxi.aop.ddl.builtins import Audio
from fuxi.aop.edsl import State, Action, Observation, MemState
from typing import List, Set, Dict, Tuple, Optional, Callable, TypeVar, Generic, Any, Union, Literal
from sdk.aop_dataclasses import CheckEnum, ASR_AgentObservation, ASR_AgentState, ASR_AgentAction, ASR_AgentMemState
async def main():
aop = await AOP.init(task_type = sdk.ASR_Annotation_Task, config = sdk.get_server_config("11017"))
agent = await aop.create_agent(sdk.ASR_Agent)
count = 3
while count > 0:
audio1 = await builtins.Audio.from_path_async('./test.wav','wav')
a = Observation[Audio](audio1)
output = await agent.audio_annotation(a) # call capability function
print(output.confidence)
await asyncio.sleep(1)
count -= 1
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
客户端-发题:异步调用
- 以下示例了发送 10000 道题,异步调用智能体能力 agent.audio_annotation_async
#!/usr/bin/env mpyorth on3s
from fuxi.aop.core import AOP
from ASR_Annotation_Task_Local import sdk
from fuxi.aop.config import aopconfig_from_json_file
import asyncio
import fuxi.aop.ddl.builtins as builtins
import os
async def async_main(tick_interval_seconds: float = 0.5):
aop = await AOP.init(task_type = sdk.ASR_Annotation_Task, config = sdk.get_server_config("10879"))
myagent_Aop_Agent = await aop.create_agent(sdk.ASR_Agent)
count = 10000
while count > 0:
input = await builtins.Audio.from_path_async('./hugege.wav','wav')
await myagent_Aop_Agent.audio_annotate_async(input)
await asyncio.sleep(1)
count -= 1
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(async_main())客户端-从数据库读取回收结果
- 一次默认 fetch 10000 条
- 以下示例假设通过 750 次,拿取 750w 条数据
dataset_instance = agent.audio_annotation.dataset
for i in range(750):
all_records = await dataset_instance.fetch(offset=i*10000) 串联任务客户端示例
以下客户端示例代码展示了如何发送多个串联任务:
- 每一个串联任务包含了两个能力。第一个能力返回了一个标注结果;根据第一个能力的返回结果判断是否调用第二个能力。
- 需要使用多协程,发多个串联任务。
请根据实际业务情况,参考对应注释的逻辑,编写客户端代码。
#!/usr/bin/env python3
from fuxi.aop.core import AOP
from SpeechSensitiveDetection_Local import sdk
from fuxi.aop.config import aopconfig_from_json_file
import asyncio
import fuxi.aop.ddl.builtins as builtins
import os
import codecs
from fuxi.aop.common.context_manager import open_session
async def async_main(tick_interval_seconds: float = 0.5):
audio_format = 'ogg'
audio_path = '/data/code/1220/ogg'
trans_fname = 'trans.txt'
aop = await AOP.init(task_type = sdk.SpeechSensitiveDetection, config = sdk.get_server_config("10879"))
asr_Agent = await aop.create_agent(sdk.SpeechSensitiveDetection_Agent)
# 创建多协程,用于发多个串联任务
loop = asyncio.get_event_loop()
with codecs.open(trans_fname, 'r', 'utf8') as inf:
lines = inf.readlines()
for l in lines:
items = l.strip().split('\t')
if len(items) == 2:
fname = os.path.join(audio_path, '{}.{}'.format(items[0], audio_format))
text = items[1].strip()
# 每一个协程,发一个串联任务
loop.create_task(asr_annotation(asr_Agent, fname, audio_format, text))
while True:
await asyncio.sleep(1)
# 定义串联任务
async def asr_annotation(agent: sdk.SpeechSensitiveDetection_Agent, fname: str, audio_format: str, text_pre_annotation: str):
async with open_session():
audiof = await builtins.Audio.from_path_async(fname, audio_format)
a = Observation[Audio](audiof)
# 调用第一个能力返回了一个标注结果,是、否
result = await agent.ssd(a)
# 根据第一个能力的返回结果判断是否调用第二个能力
if result.value == sdk.aop_dataclasses.SensitiveEnum.否:
await agent.asr_async(audiof, text_pre_annotation)
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(async_main())